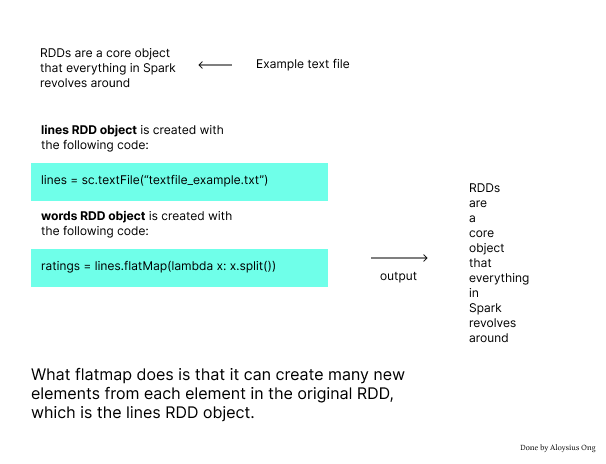
RDDs are a core object that everything in Spark revolves around. It is fundamentally an abstraction for a giant set of data.
The map function creates a 1 to 1 relationship for every entry in the RDD. Every entry in the original RDD gets mapped to a new value in the new RDD. The flatmap function works the same way as the map function, but you can have have multiple or no results per original entry.